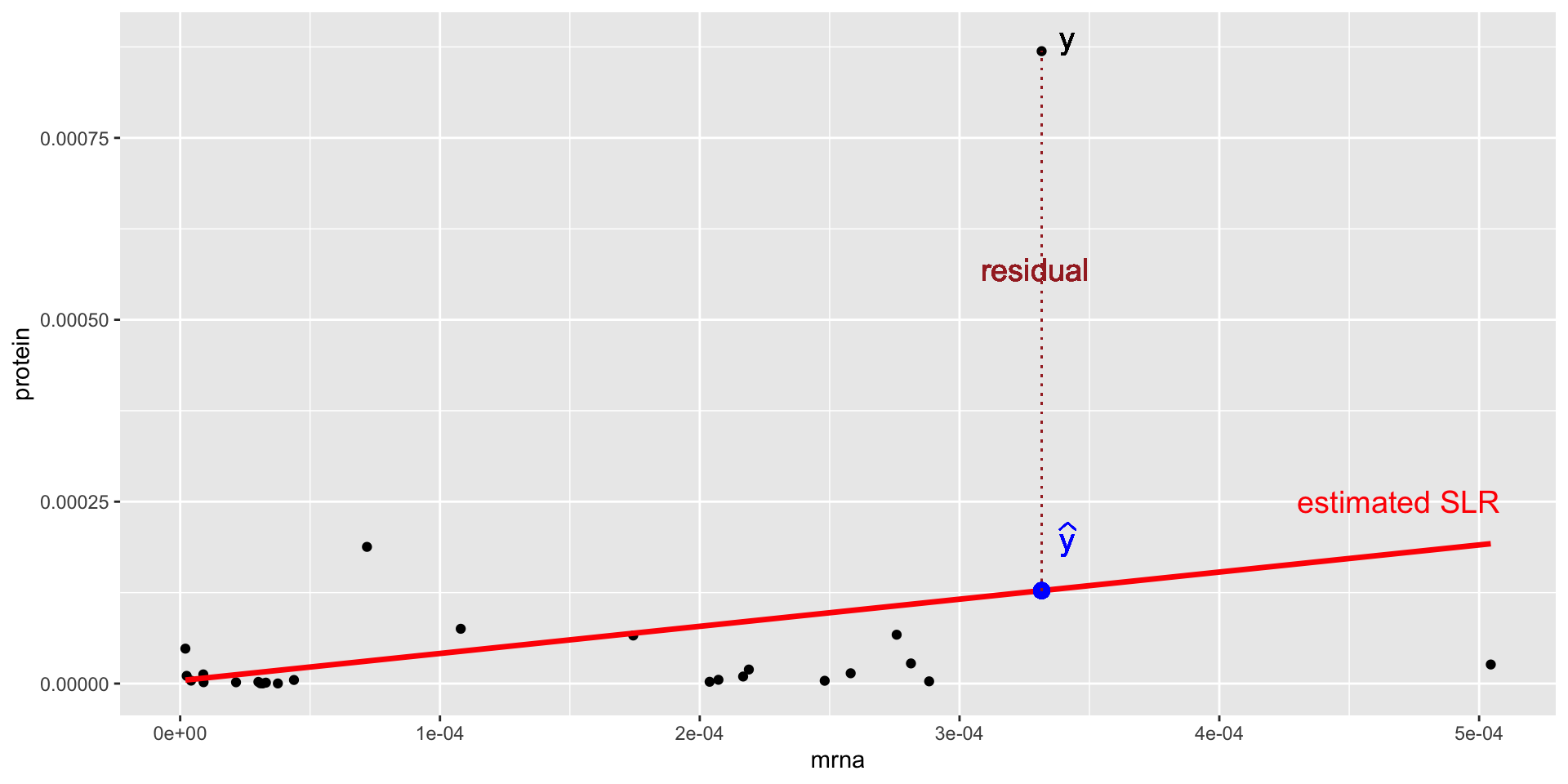
Suppose we want to use the predicted model to predict the odds of surviving for a male passenger who paid a fare of $7.25.
The predicted log-odds are
\[\begin{gather*}
\log\left(\frac{\hat{p}_s}{1 - \hat{p}_s}\right) = \underbrace{0.647}_{\hat{\beta}_0} - \underbrace{2.423}_{\hat{\beta}_1} \times 1 + \underbrace{0.011}_{\hat{\beta}_2} \times 7.25= -1.696
\end{gather*}\]
Next, by exponentiating both sides of the equation, we obtain the predicted odds:
\[
\frac{\hat{p}_s}{1 - \hat{p}_s} = e^{-1.696} = 0.183
\]
Finally, solving the above for \(\hat{p}_s\), we obtain our predicted probability of surviving
\[
\hat{p}_s = \frac{e^{-1.696}}{1+e^{-1.696}} = \frac{0.183}{1.183}=0.155
\]