\[Y_i = \beta_0 + \beta_1 \times \text{stateWashington}_{i} + \beta_2 \times \text{stateKansas}_{i} + \varepsilon_i\]
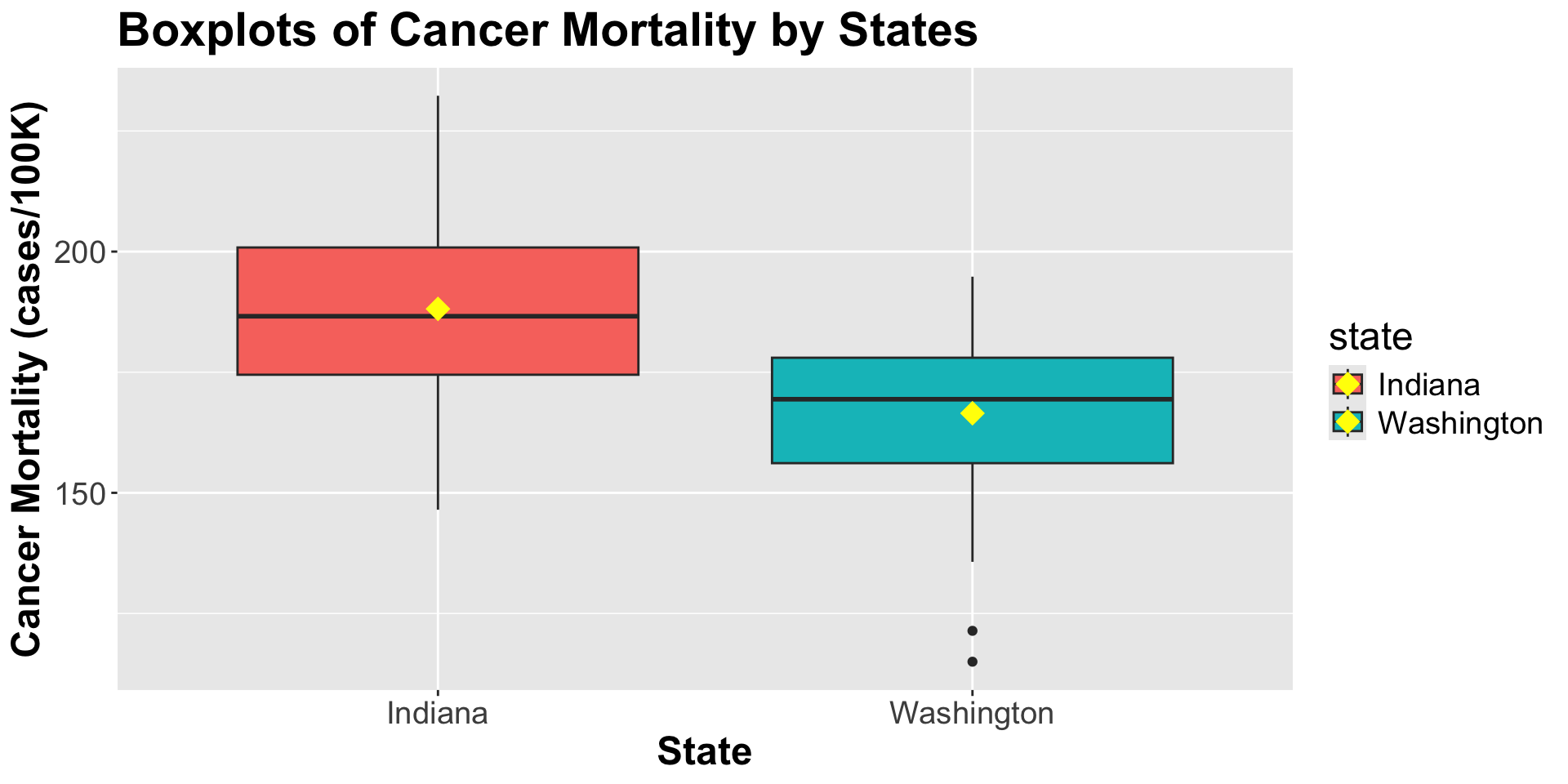
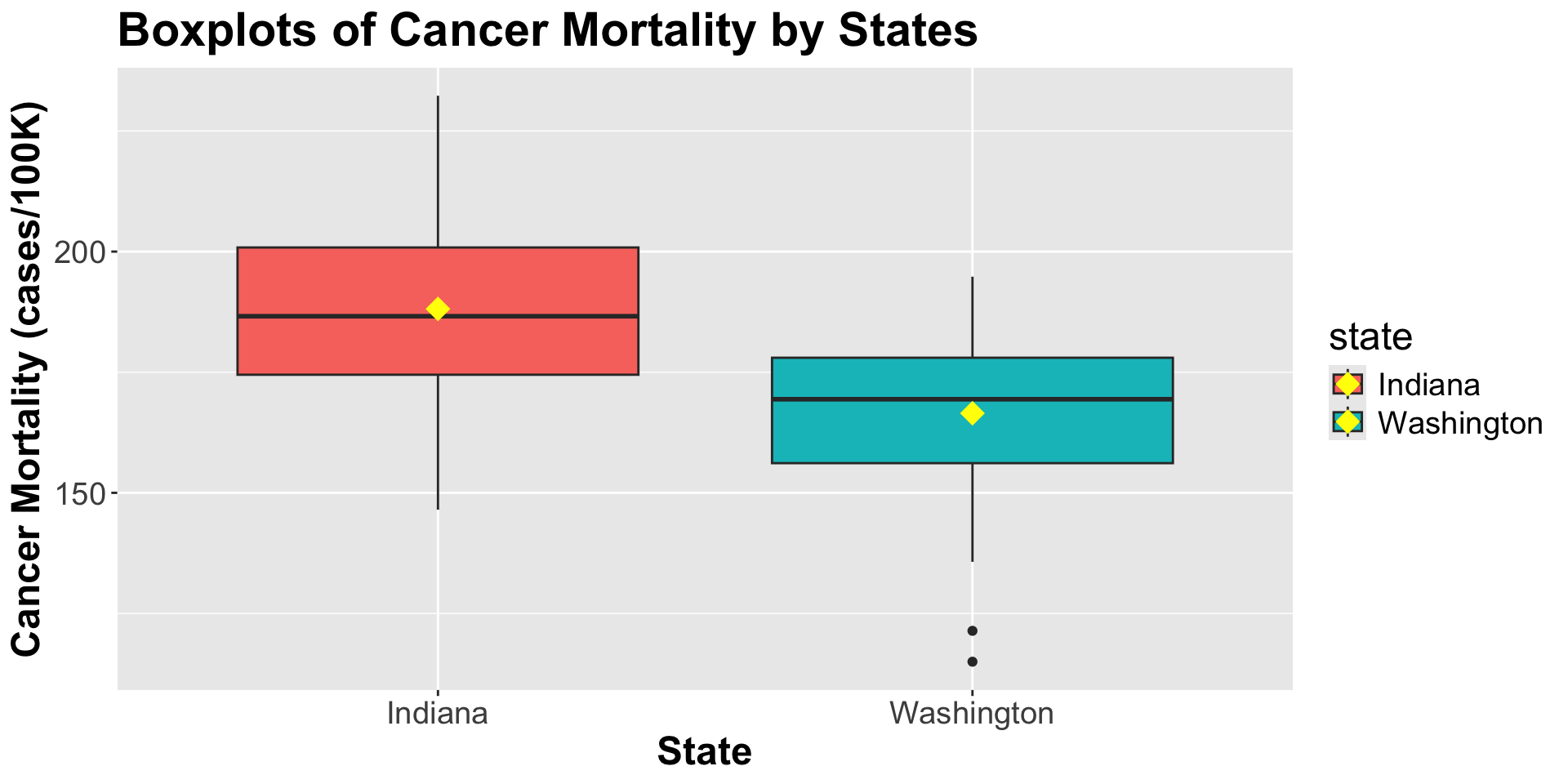
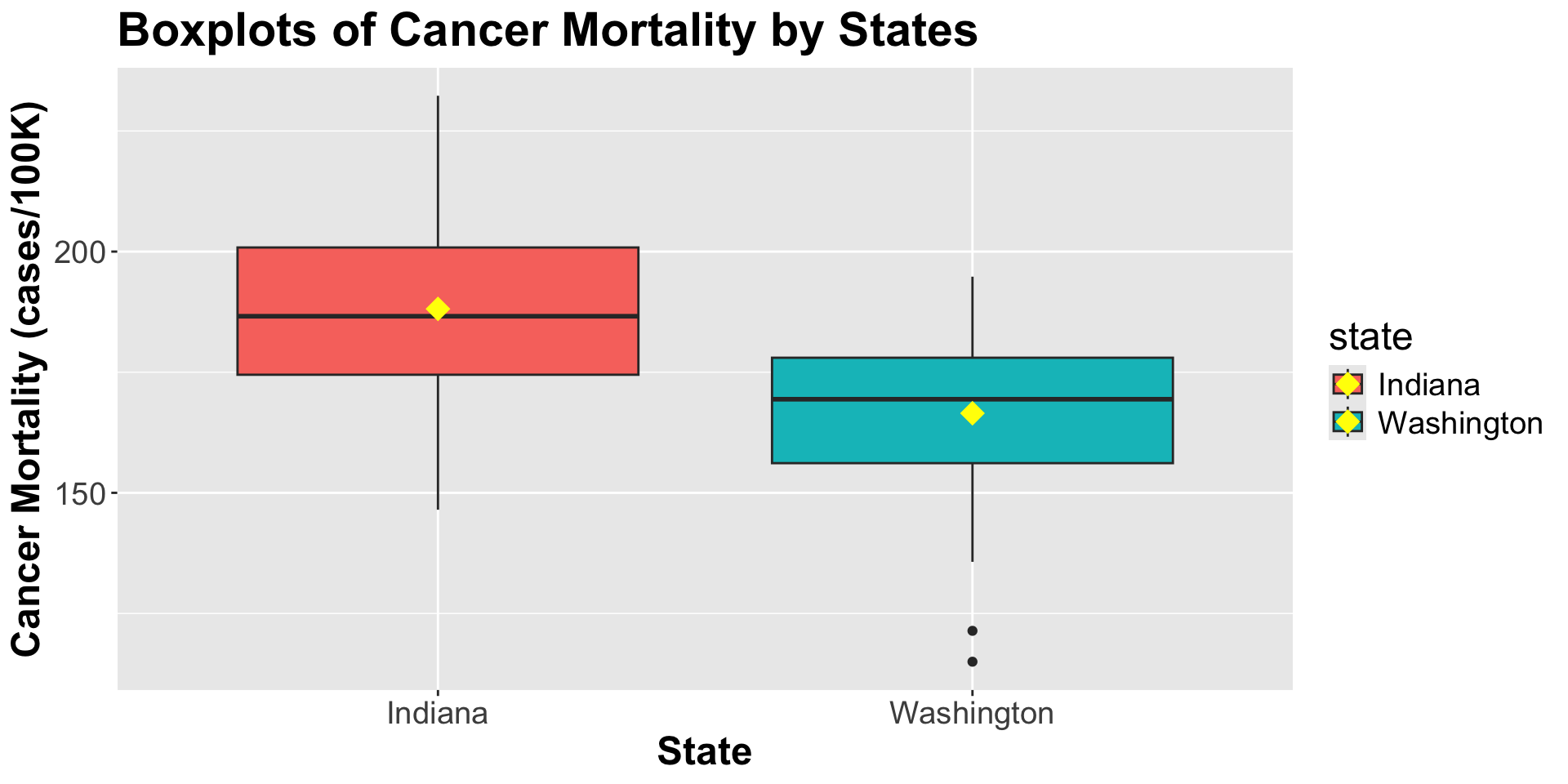
For counties in Indiana,
\(\text{stateWashington}_{i} = \text{stateKansas}_{i} = 0\), then \[Y_i = \beta_0 + \beta_1 \times 0 + \beta_2 \times 0 + \varepsilon_i\]
So we get,
\[Y_i = \beta_0 + \varepsilon_i\]
\[E[Y_i|\text{Indiana}]= \beta_0 \]
For counties in Washington,
\(\text{stateWashington}_{i} = 1\) and \(\text{stateKansas}_{i} = 0\), then
\[Y_i = \beta_0 + \beta_1 \times 1 + \beta_2 \times 0 + \varepsilon_i\]
So we get,
\[Y_i = \beta_0 + \beta_1 + \varepsilon_i\]
\[E[Y_i|\text{Washington}]= \beta_0 + \beta_1\]
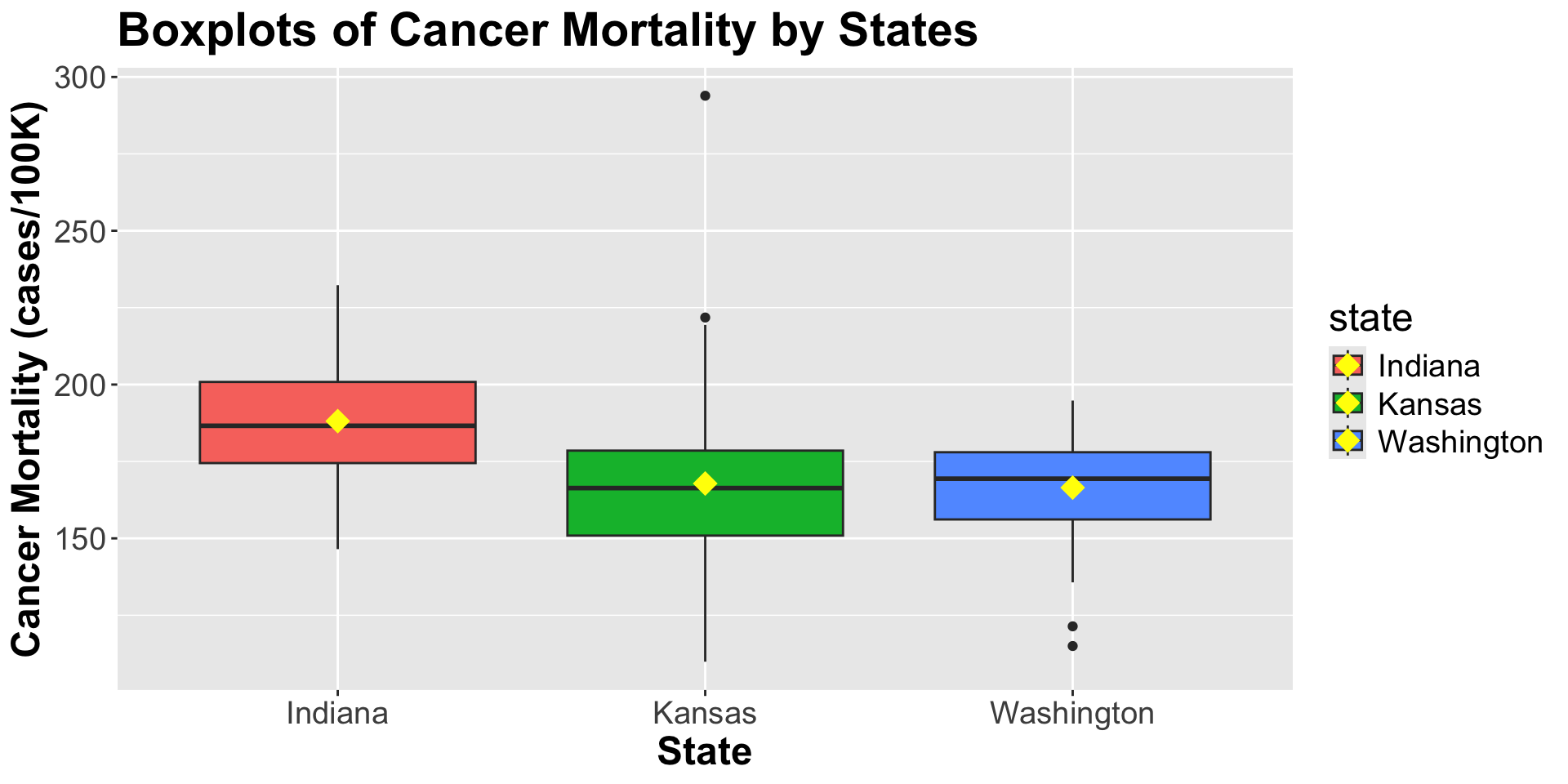
For counties in Kansas,
\(\text{stateWashington}_{i} = 0\) and \(\text{stateKansas}_{i} = 1\), then
\[Y_i = \beta_0 + \beta_1 \times 0 + \beta_2 \times 1 + \varepsilon_i\]
So we get,
\[Y_i = \beta_0 + \beta_2 + \varepsilon_i\]
\[E[Y_i|\text{Kansas}]= \beta_0 + \beta_2\]