Model Evaluation
Goodness of Fit for Logistic and Poisson
Deviance
Scroll down to see full content
Beyond MLR, a quantity called the deviance is used to measure the difference between the log-likelihoods the estimated model and that of a perfect model, known as the saturated model, which fits the data perfectly.
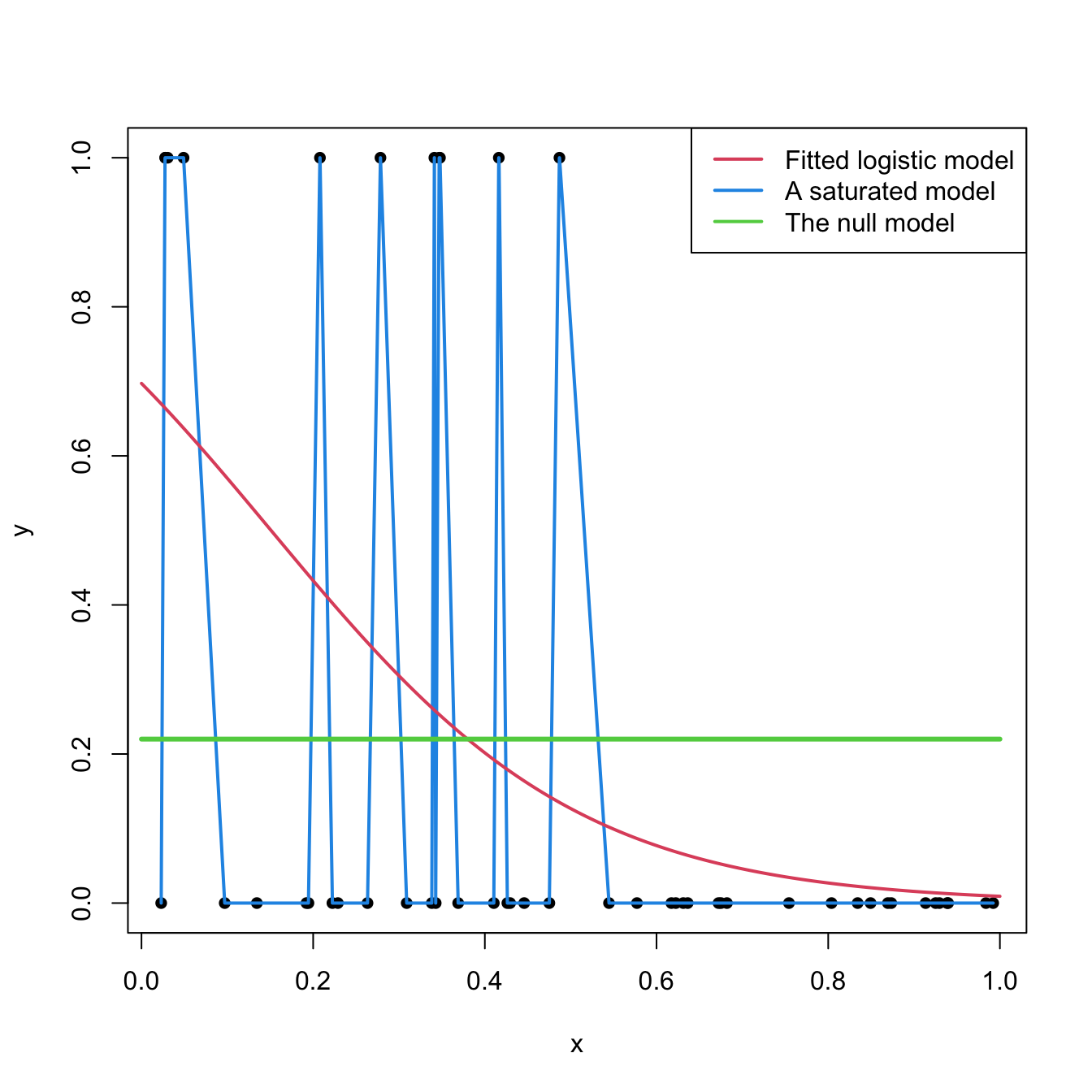 Image from Notes for Predictive Modeling
Image from Notes for Predictive Modeling
Deviance to test
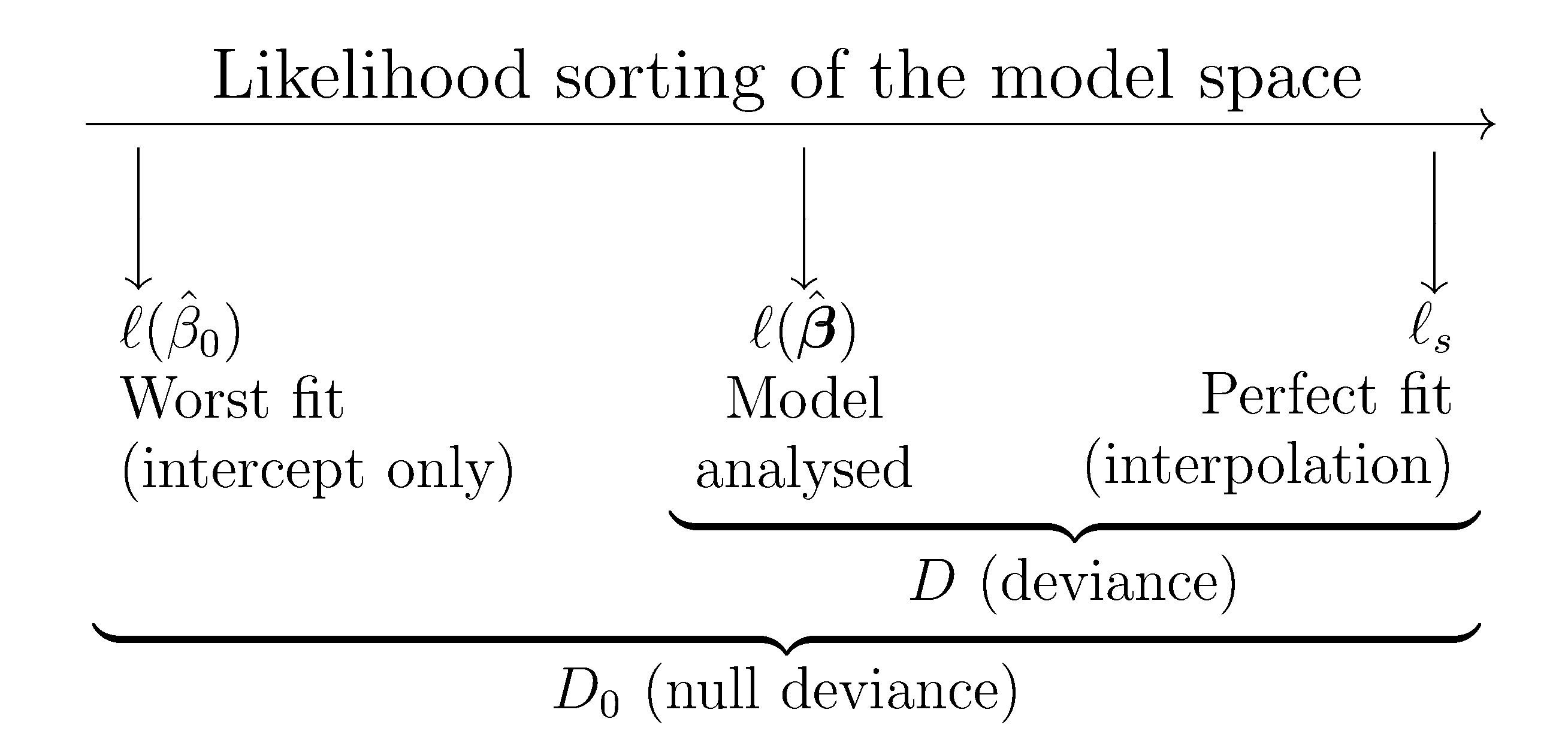
Image from Notes for Predictive Modeling
The deviance can also be used to compare nested models (similar to the \(F\)-test in LR).
The test that compares deviances has a \(\chi^2\) distribution.