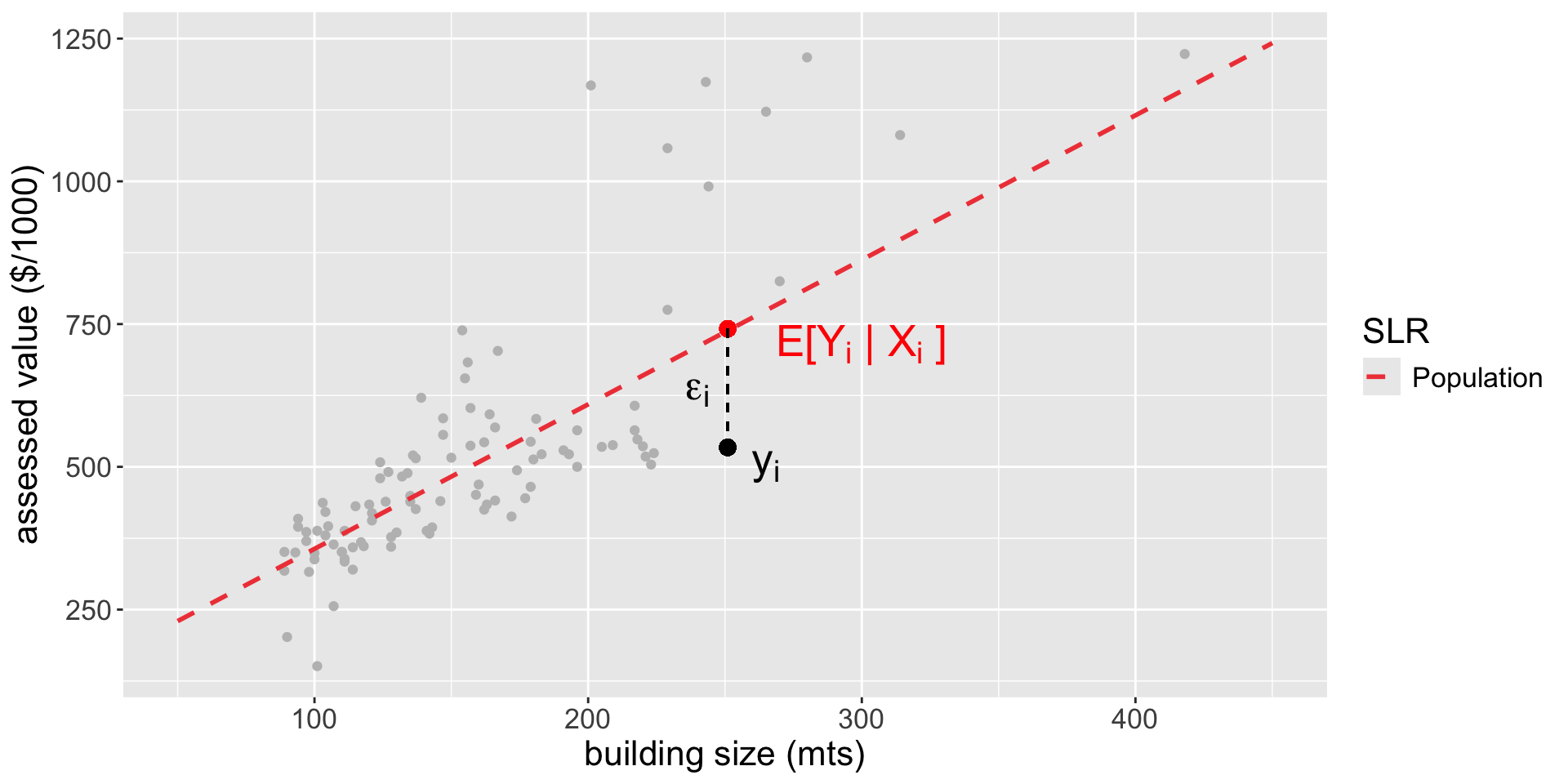
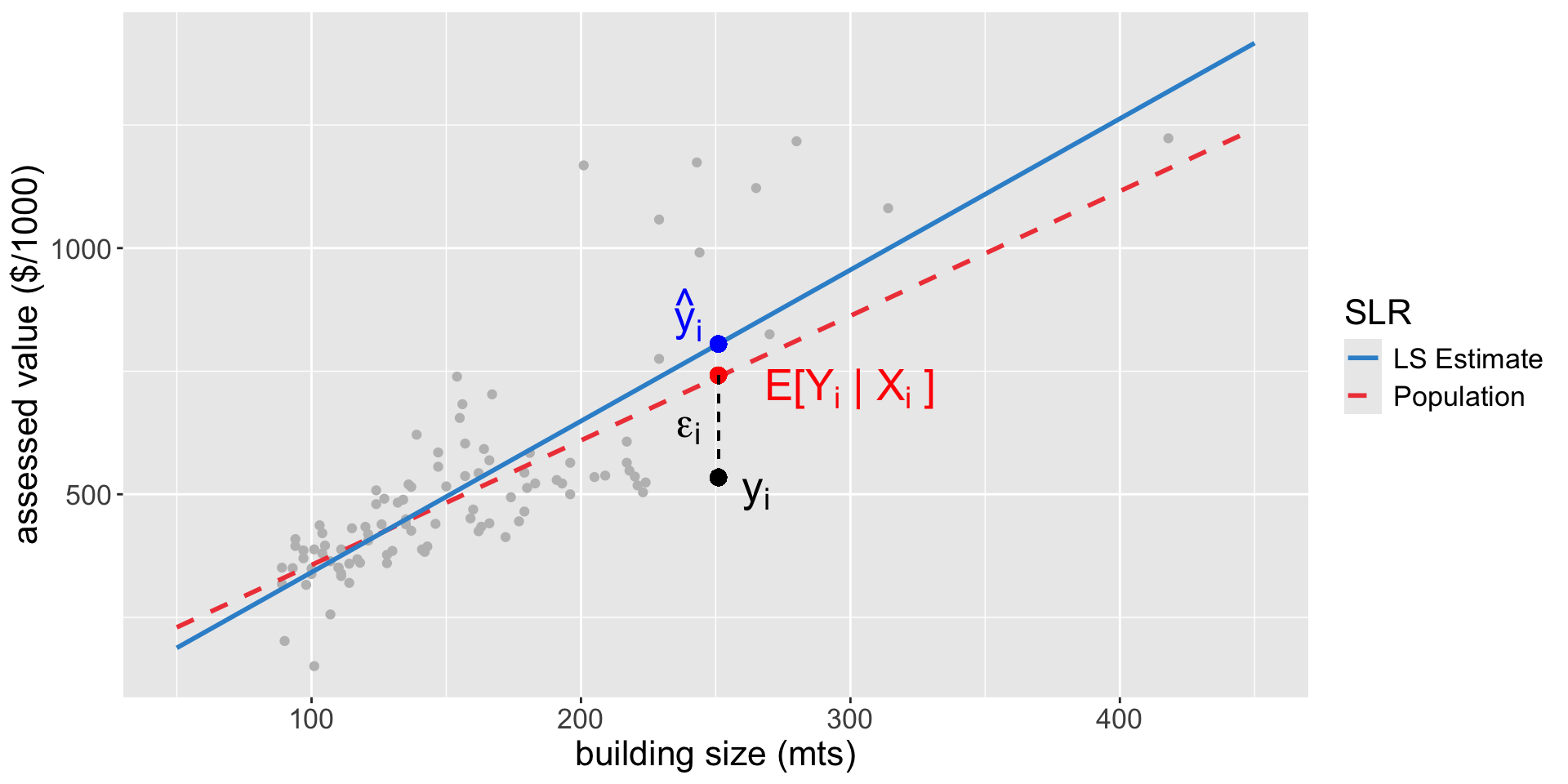
CIP are used when we want to predict \(E[Y_i|X_i]\) (conditional expectation)!
The predicted value \(\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1 X_{i}\) approximates, with uncertainty, the population average value \(E[Y_i| X_{i}] = \beta_0 + \beta_1 X_{i}\)
if we take a different sample, we get different estimates (i.e., different blue lines) and, consequently, different predictions
The only source of variation here is the sample-to-sample variation
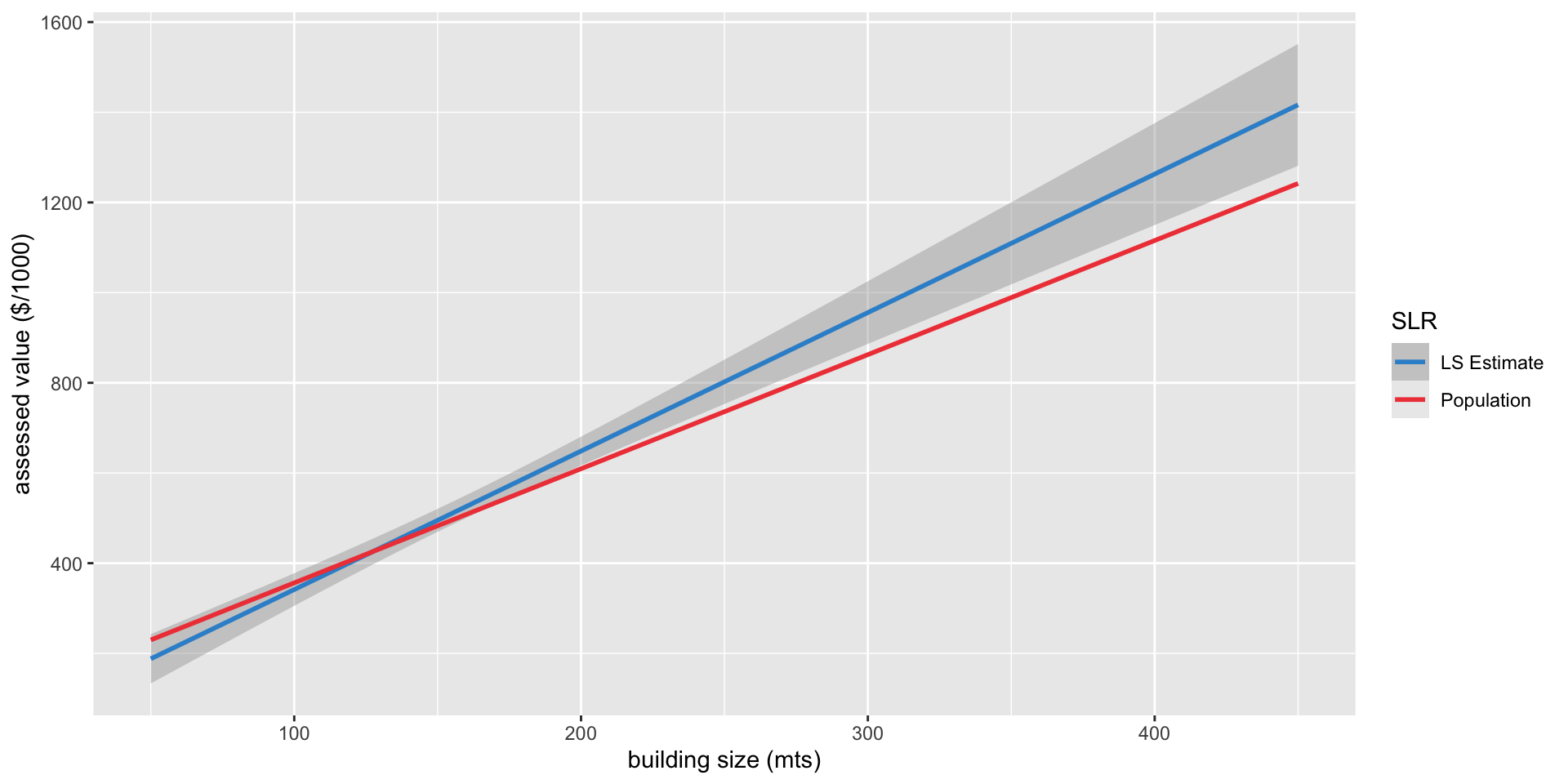
A 95% confidence interval for prediction is a range that has a 95% probability of capturing the population average value of a house with size \(X_i\)
Once we have estimated and predicted values, the range is non-random so we use the word confidence (instead of “probability”) since nothing else is random!